
- Hay muchas relaciones conocidas entre las variables macroeconómicas en economía. Algunas de ellas incluso se presentan como “leyes”, por ejemplo, la oferta monetaria e inflación o tasas de interés de referencia e inflación. Sin embargo, los modelos económicos bien conocidos suelen utilizar solo una pequeña cantidad de variables. Hoy en día, con los avances en el aprendizaje automático o machine learning y campos de macrodatos, estos modelos establecidos podrían mejorarse.
Una posible solución se presenta en el artículo de investigación de Yang et al. (2020). Los autores construyen gráficos de conocimiento donde conectan variables ampliamente reconocidas como el PIB, la inflación, etc., con otras variables más o menos conocidas a partir de datos masivos de revistas financieras e informes de investigación publicados por los principales think tanks, consultoras o compañías de gestión de activos.
Con la ayuda del procesamiento avanzado del lenguaje natural, es posible básicamente “leer” todas las investigaciones publicadas relevantes y encontrar las relaciones entre las variables macroeconómicas. Si bien esta tarea podría llevar años a los lectores “humanos”, el método de aprendizaje automático puede revisar estos textos en un tiempo mucho más corto.
Además, el uso de los gráficos de conocimiento se muestra en un problema de pronóstico de inflación o inversión. Como muestra el artículo, los gráficos de conocimiento podrían utilizarse para la selección de variables con la capacidad de encontrar relaciones alternativas y novedosas. Por último, los pronósticos basados en gráficos de conocimiento también se comparan con el enfoque de “línea de base” más tradicional, y los autores comparan los métodos en períodos de pronóstico tanto a corto como a largo plazo.
- Autores: Yucheng Yang, Yue Pang, Guanhua Huang y Weinan E
- Título: The Knowledge Graph for Macroeconomic Analysis with Alternative Big Data (El gráfico de conocimiento para el análisis macroeconómico con Big Data alternativo)
- Enlace : https://arxiv.org/abs/2010.05172
Resumen:
El actual sistema de conocimiento de la macroeconomía se basa en interacciones entre un pequeño número de variables, ya que los modelos macroeconómicos tradicionales pueden manejar principalmente un puñado de insumos. Un trabajo reciente que utiliza macrodatos sugiere que un número mucho mayor de variables están activas para impulsar la dinámica de la economía agregada. En este artículo, presentamos un gráfico de conocimiento (KG) que consiste no solo en vínculos entre variables económicas tradicionales sino también en nuevas variables alternativas de big data. Extraemos estas nuevas variables y los vínculos aplicando herramientas avanzadas de procesamiento del lenguaje natural (PNL) en los datos textuales masivos de la literatura académica y los informes de investigación. Como ejemplo de las aplicaciones potenciales, lo usamos como conocimiento previo para seleccionar variables para modelos de pronóstico económico en macroeconomía.
Como siempre presentamos varias figuras interesantes:
Citas notables del trabajo de investigación académica:
“Todo el sistema de conocimiento de la macroeconomía se basa en nuestra comprensión de las interacciones entre este pequeño número de variables. Con el auge del big data y el aprendizaje automático, ahora tenemos la oportunidad de desarrollar modelos más sofisticados con una cantidad mucho mayor de variables (McCracken y Ng, 2016; Coulombe et al., 2019). Para hacer esto de manera efectiva, se necesita un nuevo sistema de conocimiento que describa tanto las relaciones estadísticas y estructurales de las variables económicas tradicionales como de las nuevas.”
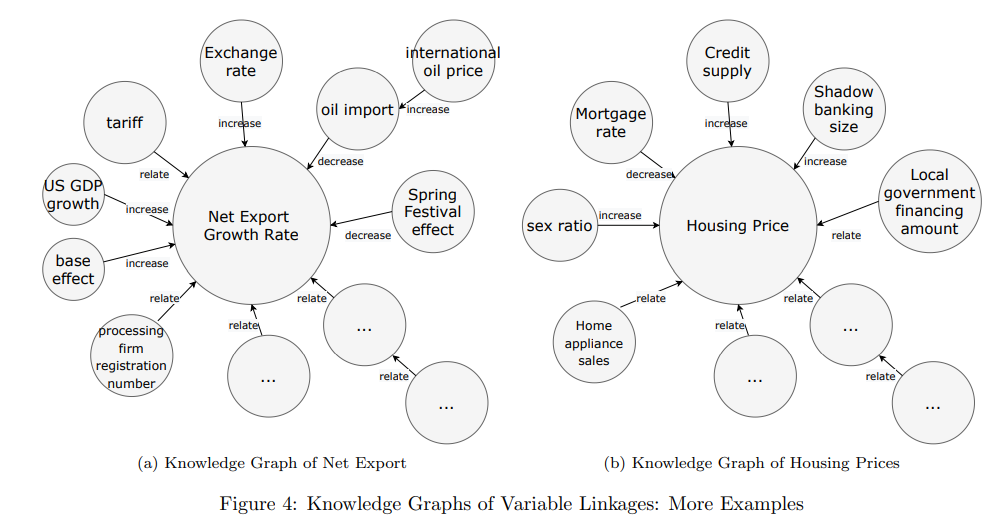
“Diseñamos un algoritmo para extraer datos textuales masivos (1) variables tradicionales de interés (como PIB, tasa de inflación, precio de la vivienda, etc.), (2) variables de datos alternativas (como uso de electricidad, flujo de migración, etc.), como así como (3) las relaciones (correlación positiva, correlación negativa, etc.) entre estas variables. Después de un post-procesamiento que incluye la resolución de co-referencias, construimos un gráfico de conocimiento comenzando con la variable tradicional de intereses como centros, y expandiéndonos paso a paso para incluir las variables alternativas relevantes.”
“El gráfico de conocimiento que construimos proporciona un nuevo sistema de conocimiento para la macroeconomía y tiene muchas aplicaciones potenciales. Una aplicación que nos interesa especialmente es la formulación de la macroeconomía como un problema de aprendizaje reforzado (RL) (Sutton y Barto, 2018; Silver et al., 2016). Un marco de RL consta de los siguientes componentes esenciales: el espacio de estados y el entorno, el espacio de acción, la dinámica del sistema y las funciones de recompensa. En este sentido, el gráfico de conocimiento de los vínculos entre las variables económicas juega el papel del espacio de estados y el medio ambiente.”
“En este artículo, también aplicamos el gráfico de conocimiento de las variables económicas
a una tarea simple pero más concreta: la selección de variables en la previsión económica. A diferencia del trabajo anterior que utiliza herramientas estadísticas para hacer la selección de variables, utilizamos el gráfico de conocimiento como conocimiento previo para seleccionar variables para modelos de pronóstico económico. Veremos que, en comparación con los métodos estadísticos, el método basado en KG logra una precisión de pronóstico significativamente mayor, especialmente para los pronósticos a largo plazo.”
“Para diferentes períodos de pronóstico (de un mes a 12 meses), los errores de pronóstico en los conjuntos de prueba para el modelo de línea de base y el modelo basado en KG se presentan en la Figura 5. Reportamos el error porcentual absoluto medio (MAPE) en los paneles de la izquierda. y la raíz del error cuadrático medio (RMSE) en los paneles de la derecha, y los resultados son cualitativamente iguales. Para el pronóstico de la inflación (paneles superiores), en comparación con el modelo de referencia, el modelo basado en KG logra una mayor precisión de pronóstico en general. En el pronóstico a corto plazo (dentro de cinco meses), los errores de pronóstico para ambos modelos son comparables entre sí, y el modelo de línea de base incluso supera al modelo basado en KG en algunos horizontes. Sin embargo, en la previsión a largo plazo, el rendimiento del modelo de línea de base empeora, mientras que el modelo basado en KG logra una precisión estable y mucho mayor que el método de referencia. Argumentos similares también son válidos para los pronósticos de inversión nominal. La tendencia general revelada por la Figura 5 es consistente con nuestra expectativa de que el pronóstico a corto plazo se basa más en los datos, mientras que el pronóstico a largo plazo se basa más en capturar la lógica subyacente del problema. El modelo de línea de base es más un modelo puro basado en datos, mientras que el modelo basado en KG intenta capturar la lógica subyacente. El mejor desempeño a largo plazo del modelo basado en KG sirve como confirmación de que las relaciones descritas en el gráfico de conocimiento representan correctamente la verdadera lógica del sistema económico que se investiga ”. La tendencia general revelada por la Figura 5 es consistente con nuestra expectativa de que el pronóstico a corto plazo se basa más en los datos, mientras que el pronóstico a largo plazo se basa más en capturar la lógica subyacente del problema. El modelo de línea de base es más un modelo puro basado en datos, mientras que el modelo basado en KG intenta capturar la lógica subyacente. El mejor desempeño a largo plazo del modelo basado en KG sirve como confirmación de que las relaciones descritas en el gráfico de conocimiento representan correctamente la verdadera lógica del sistema económico que se investiga ”. La tendencia general revelada por la Figura 5 es consistente con nuestra expectativa de que el pronóstico a corto plazo se basa más en los datos, mientras que el pronóstico a largo plazo se basa más en capturar la lógica subyacente del problema. El modelo de línea de base es más un modelo puro basado en datos, mientras que el modelo basado en KG intenta capturar la lógica subyacente. El mejor desempeño a largo plazo del modelo basado en KG sirve como confirmación de que las relaciones descritas en el gráfico de conocimiento representan correctamente la verdadera lógica del sistema económico que se investiga”.





